
Offlate, I had been working on a lot of cases where copies are inherent. I also noticed that data occupied by copies is a lot more than the actual production data in many cases. Hence I decided to rebound back into writing my blog with “Point in Time Copy Services “(which many people would identify as snapshots or flashcopy or copies).
Point in Time Copies
The Storage Networking Industry Association (SNIA) defines a point-in-time copy as:
A fully usable copy of a defined collection of data that contains an image of the data as it appeared at a single point-in-time. The copy is considered to have logically occurred at that point-in-time, but implementations may perform part or all of the copy at other times, as long as the result is a consistent copy of the data that appeared at a particular point-in-time.
Before the invention of point-in-time copy, to create a consistent copy of the data, the application had to be stopped while the data was physically copied. For large data sets, this could easily involve a stoppage of several hours, this overhead meant that there were practical limits on making copies. Today’s point-in-time copy facilities allow a copy to be created with almost no impact on the application; in other words, other than perhaps a very brief period of seconds or minutes while the copy or bitmap is established, the application can continue running.
Over the years many point in time copies have been developed. In these blog series, I am going to explain the benefits and drawbacks of various point in time copy and the architecture and operations considerations and how they are used in the industry.
Snapshots
Snapshot is a commonly used industry term (also called space-efficient copies) is an ability to capture or record the state of data at any given moment or point in time and preserve that snapshot as a guide to restore the data in case of a failure of the storage device. Typically, snapshot copy is done instantly and made available for use by other applications such as backup, UAT, reporting, and data replication applications. The original copy of the data continues to be available to the applications without interruption, while the snapshot copy is used to perform other functions on the data.

Figure 1: Snapshot Copies
Snapshots enable better application availability, faster recovery, easier back up management of large volumes of data, reduces exposure to data loss, virtual elimination of backup windows, and lowers total cost of ownership (TCO) because it doesn’t occupy any space unless the production data is changed.
There different approaches to the way snapshots are implemented or are made. Each approach has its own benefits and drawbacks. It is very important to understand the various approaches and how they fit in your need or for various applications. Below mentioned are the most commonly used methodologies;
Copy on Write (CoW):
When the snapshot is first created, only the meta-data about where original data is stored is copied. No physical copy of the data is done at the time the snapshot is created. Therefore, the creation of the snapshot is time and space efficient.

Figure 2: Snapshots when first created (Only Bitmap or metadata gets copied)
As blocks on the original volume change, the original data is copied (moved over) into the pre-designated space (reserved storage capacity) set aside for the snapshot prior to the original data being overwritten. The original data blocks are copied just once at the first write request (after the snapshot was taken; this technique is also called copy-on-first-write). This process ensures that snapshot data is consistent with the exact time the snapshot was taken, and is why the process is called “copy-on-write.”
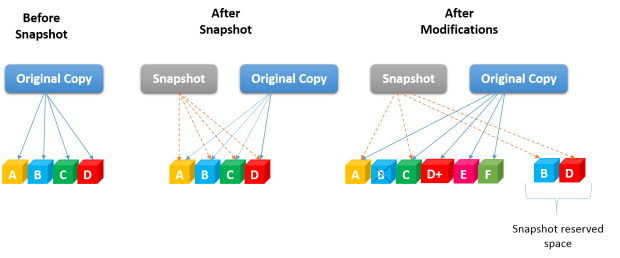
Figure 3: Copy on Write (CoW) Snapshots
After the initial creation of a snapshot, the snapshot copy tracks the changing blocks on the original volume as writes to the original volume are performed. Hence the implementation of “copy-on-write” snapshots requires the configuration of a pre-designated space (typically 10-20% of the size of volume/LUN) to store the snapshots.
Pros of Copy on Write:
- In workloads that use easy tiering, where the hot data is sitting on the SSD or Flash and a snapshot is taken and when a change or update happens on the hot data, then the snapshot algorithm moves the old data block on SSD to SAS and writes the new data on SSD thus maintaining the performance even when data is updated. Hence it becomes very important to choose the right snapshot implementation approach based on your workload.
Cons of Copy on Write:
Any changes/updates to the original volume are performed have double write penalty. Following is what that happens:
- File system reads in original data blocks (1 x read I/O penalty) in preparation for the copy. In the figure 3 blocks B and D will be updated with new data.
- Once original data (B, D) is read by the production LUN, data is copied (1 x write I/O penalty) into the designated storage pool that is set aside for the snapshot before original data is overwritten, hence the name “copy-on-write”. (Figure 3)
- It then writes the new and modified data blocks (B (deleted), D+) to original data block location (1 x write I/O penalty) and re-link the blocks to the original snapshot. (Figure 3)
In short, a write (change/update) to a volume having copy on write snapshot takes:
- 1 read (1 x read I/O) and
- 2 writes (2x write I/O)
Thus, it becomes very important to see what kind of workload you are using it for.
Redirect on Write (RoW):
Like copy on write, when the snapshot is first created, even in redirect on write only meta-data about where original data is stored is copied. Redirect on write is also time and space efficient. By design a redirect on write (RoW) snapshot is optimized for write performance so any changes/updates are redirected to new blocks. Instead of writing one copy of the original data to a snapshot reserved space (cache, LUN reserve, or snapshot pool as described by various vendors) plus a copy of the changed data that is required with copy on write (CoW), redirect on write (RoW) writes or redirects only the changed data to new blocks.

Figure 4: Redirect on Write (RoW) Snapshots
Pros of Redirect on Write:
Any changes/updates to the original volume are performed as follows:
- The filesystem writes updates to new blocks. Filesystem keeps track of available blocks, which allows for changes to be done very efficiently. For example, as data blocks (B, D) are changed/updated, pointers in the active file system or the original copy are redirected to new blocks (B(deleted), D+); however the snapshot pointers still point to the original blocks to preserve that point-in-time image. (Figure 4)
In short, a write to a volume takes:
- 1 write (1x write I/O)
Cons of Redirect on Write:
- With redirect-on-write, the original copy contains the point-in-time data, that is, snapshot, and the changed data reside on the snapshot storage. When a snapshot is deleted, the data from the snapshot storage must be reconciled back into the original volume.
- As multiple snapshots are created, access to the original data, tracking of the data in snapshots and original volume, and reconciliation upon snapshot deletion is further complicated.
- The snapshot relies on the original copy of the data and the original data set can quickly become fragmented.
- While working in tandem with solutions like easy tiering, if the hot data is on SSD or Flash and it has to be edited then the new update will be moved to SAS drives. Hence causing the performance impact.
Therefore, it becomes very important to understand the type of workloads and the type of storage being used to plan your snapshot implementation approach accordingly.
After reading so much about snapshots, I am sure you might already be thinking of when and why we should be using each of the snapshots. I am ending this blog with snapshots but please don’t come to a conclusion that I have finished explaining about point in time copies. There is lot more to understand about point in time copies and many more types of copies to help you in planning your storage implementation accordingly.
References: SNIA, IBM Developer Works IBM Redbooks

More than workload, the snapshot methodology needs to be governed by storage architecture. For example, XIV like storage, where there are no hotspots and flash is used for caching only, OR A9K architecture where data is all flash, redirect on write is actually an optimised way of doing things.
SVC like architectures, where storages are designed to be hybrid, data is expected to move across controllers, and snapshots may be offloaded to low performing storages etc, copy on write is a better choice.
SVC is optimized design, because it does not cause exponential write amplification for cascaded copy on write snapshots, howoever still maintains the expected tiring for production workload.
LikeLike
Yes Shalaka. I definitely agree with your point, storage architecture is very important. I am planning to cover about it in the next few blogs.
LikeLiked by 1 person